
Probability and Statistics for Deep Learning
By the end of this note, you will understand random variables, expectation, variance, and key distributions, apply Bayes’ theorem and MLE in ML/DL settings, explain the bias–variance tradeoff and its link to overfitting and underfitting, and use core information theory concepts like entropy and KL divergence in loss functions and model evaluation.

Deep Learning - A Comprehensive Guide
Deep Learning is a subset of Machine Learning that uses multi-layered neural networks to automatically learn complex patterns from data such as images, text, audio, and video.

Backpropagation
Backpropagation (or backprop) is the algorithm used to compute the gradient of the loss with respect to every parameter in a neural network. It does this by applying the chain rule layer by layer, starting from the loss at the output and moving backward through the network.
Optimizers
An optimizer (or optimization algorithm) is the component that takes the gradients of the loss with respect to the parameters (computed by backpropagation) and produces the actual parameter updates.

Loss Functions
A loss function (or cost function) is a scalar function that measures how wrong the model’s predictions are compared to the true targets. It takes predictions and targets as inputs and outputs a single number: the higher the loss, the worse the model is doing.

Activation Functions
Think of a volume knob that doesn’t just multiply the signal linearly: it might squash loud sounds (saturation), cut off negative values (ReLU), or smoothly compress everything into a fixed range (sigmoid).

Artificial Neuron And Perceptron
An artificial neuron is the smallest computational unit in a neural network. It takes several numeric inputs, multiplies each by a weight, adds a bias, and passes the result through an activation function to produce one output.
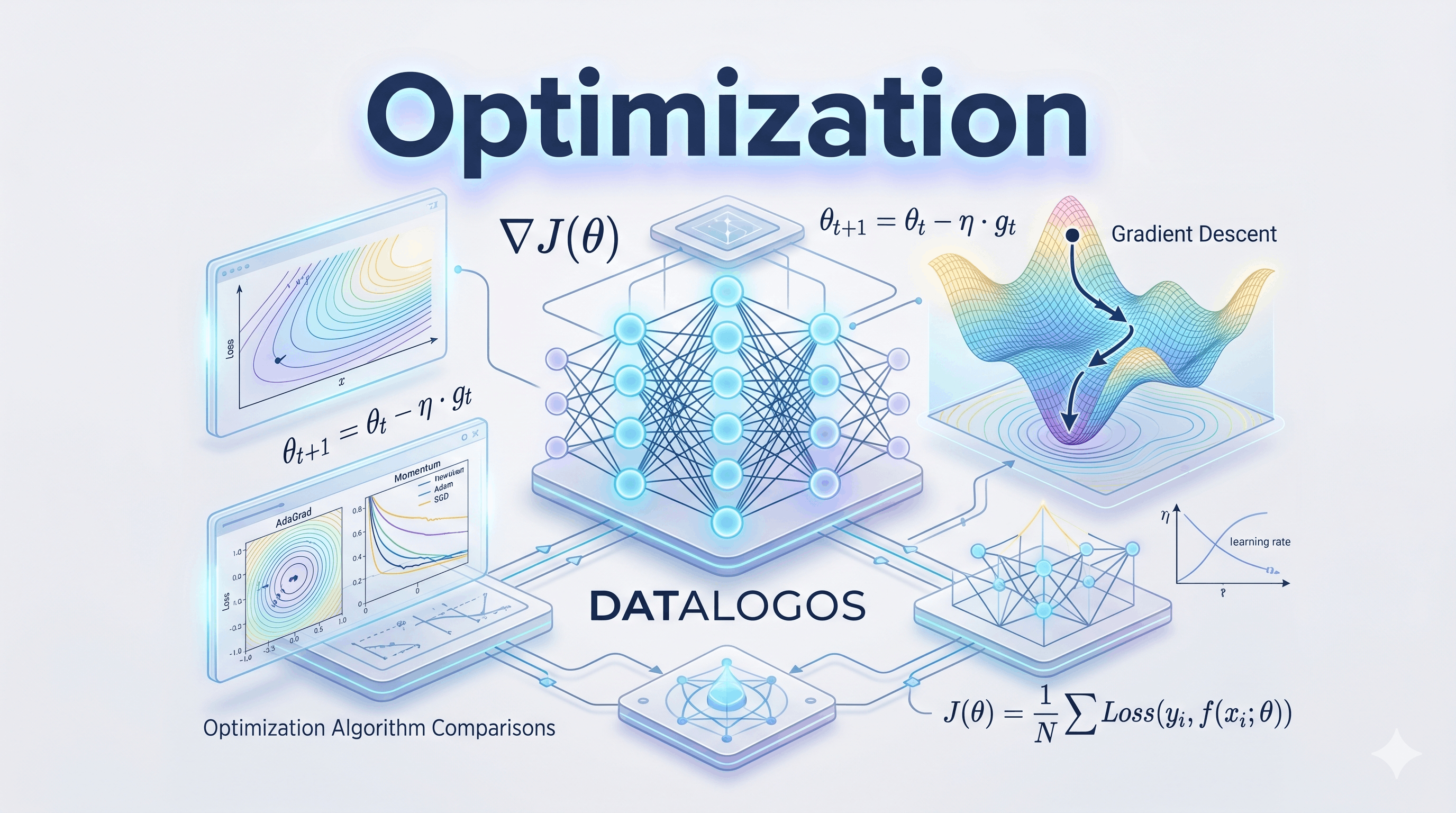
Optimization Fundamentals
Optimization in machine learning and deep learning is the process of finding parameter values (e.g., weights) that minimize a loss function

Calculus For Deep Learning
By the end of this note, you will understand derivatives, gradients, and the chain rule, how they power backpropagation and gradient descent, when to use derivative vs gradient vs Jacobian, and how to answer key deep learning calculus interview questions clearly and correctly.

Algebra for Deep Learning
This document will help you understand why linear algebra is used in deep learning, with few examples.